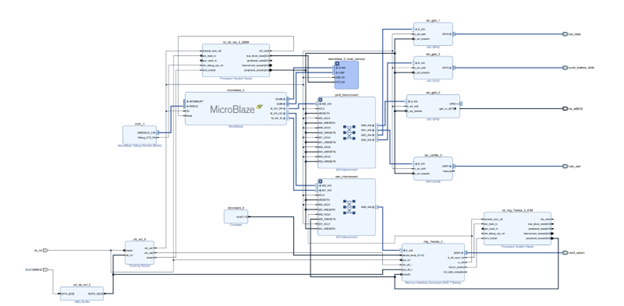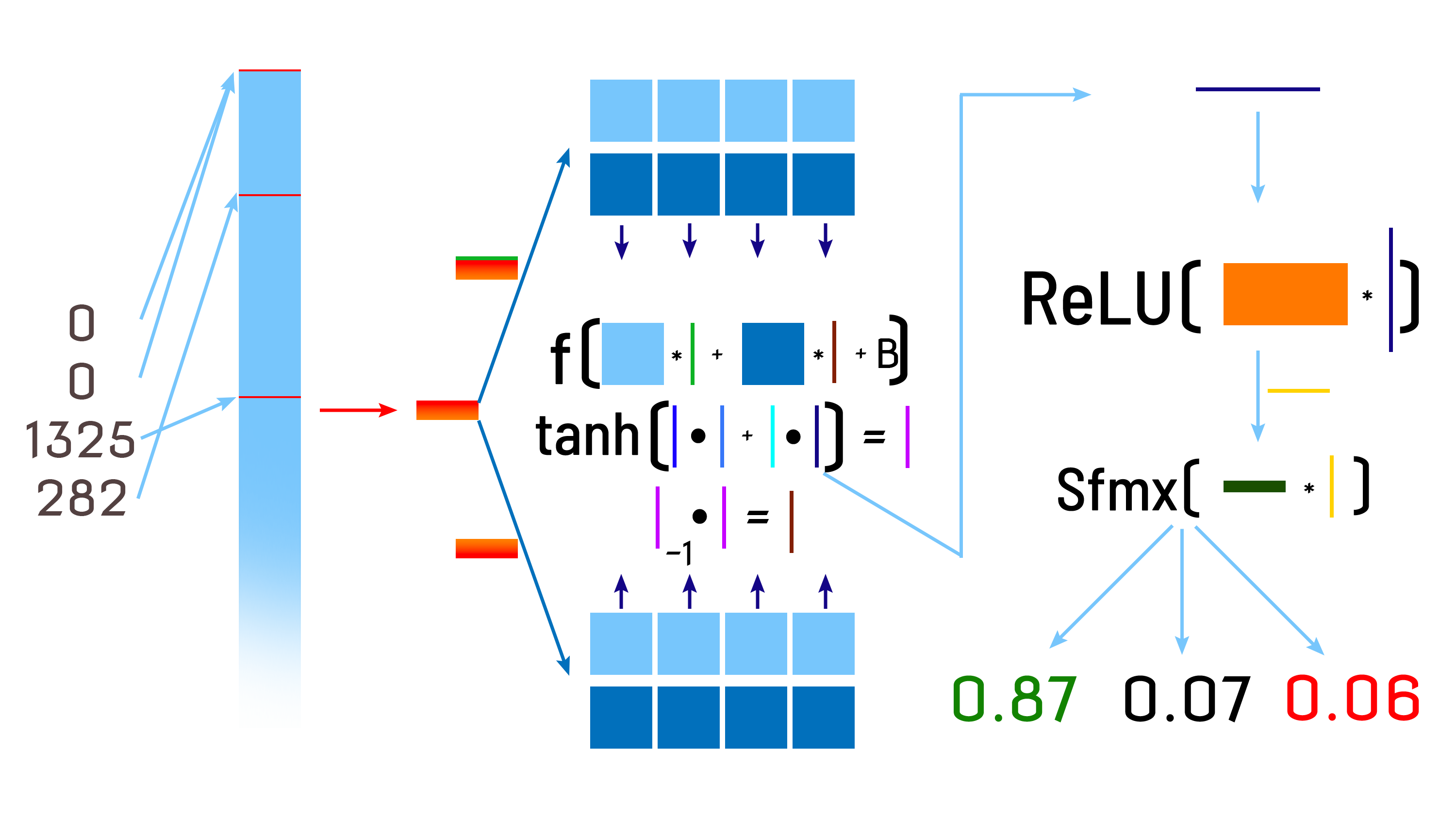
| CPU | GPU | FPGA | |||||
|---|---|---|---|---|---|---|---|
| Training | Validation | Testing | Training | Validation | Testing | Testing | |
| Time (ms) | 1.26 | 1.25 | 1.23 | 0.65 | 0.48 | 0.22 | 2160000 |
| Clock cycles | 1242 | 1232 | 1227 | 640 | 475 | 215 | n/a |
| Throughput (samples/s) | 792.26 | 769.99 | 810.07 | 4281.29 | 4353.12 | 6315.91 | 0.0037 |
| Latency (ms/sample) | 1.26 | 1.25 | 1.23 | 0.23 | 0.23 | 0.16 | 270000 |
| Accuracy (%) | 34.76 | 34.93 | 51.57 | 44 | 44 | 44 | 57 |
| Power Consumption (W) | n/a | n/a | n/a | 26.92 | 26.83 | 26.29 | 99.6 |
| Temperature (°C) | n/a | n/a | n/a | 45 | 45 | 45 | 53.5 |